



Methods and means for the automatic dynamic scientific and educational resources ordering of the global electronic information environment
In the process of work was implemented fundamentally new software architecture ащк automatic systematization of scientific and educational segment of the global electronic information environment. Scientific and educational orientation allows using the features of the relevant data, especially the fact that they can usually be classified as semi-structured. This leads to the possibility of using structured methods aimed at processing the class, including methods based on Information Extraction.
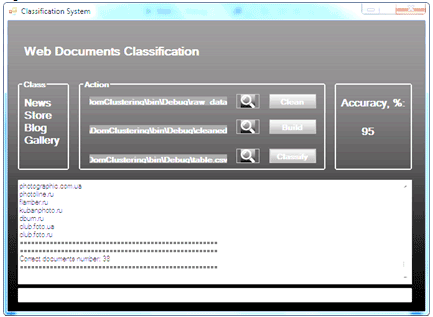
There were established methods and related software tools that implement education-oriented method of information selection, considering the desired resources in terms of context-attribute model. This presentation reveals to extract the sections of input information and perform a structured set of documents for each slice individually and collectively for their using methods Data Mining, Text Mining, Web Mining and Knowledge Discovery in Databases. One of the important advantages of this approach is the ability to process heterogeneous data, including text and multimedia (video courses, video master classes, scientific conferences, etc.). The result of the information resources structuring is metadata that describes the analyzed information, and on which is tuned search engines for the purpose of fine tuning in education information needs of the user.
Thus, through the implementation of a fully functional system that developed in the project, and software structure and algorithms of the opportunity of obtaining, structuring, and analyzing data and providing highly efficient end-user-oriented semantic search engines.
| Attachment | Size |
|---|---|
| 390.1 KB |