



Методи та засоби автоматичної систематизації динамічного науково-освітнього ресурсу глобального електронного інформаційного простору
В процесі виконання роботи було реалізовано принципово нову архітектуру програмних засобів автоматичної систематизації науково-освітнього сегменту глобального електронного інформаційного простору. Орієнтованість на науково-освітню галузь дозволила використати особливості відповідних даних, у першу чергу той факт, що їх зазвичай можна віднести до класу частково структурованих. Останнє призводить до можливості використання методів структурування, спрямованих на обробку даних цього класу, зокрема методів на базі відбору інформації (Information Extraction).
Також були створені методи та відповідні програмні засоби, які реалізують освітньо-орієнтований метод відбору інформації, що розглядає шукані ресурси з точки зору контекстно-атрибутивної моделі. Подібне подання дозволяє виділити з вхідних даних інформаційні зрізи та виконувати структурування множини документів як для кожного зрізу окремо, так і для їх сукупності з використанням методів Data Mining, Text Mining, Web Mining та Knowledge Discovery in Databases. Однією з важливих переваг такого підходу є можливість обробки гетерогенних даних, зокрема, текстомістких та мультимедійних (наприклад, відеокурсів, відеозаписів мастер-класів, науково-практичних конференцій тощо). Результатом структурування інформаційних ресурсів є метадані, які описують проаналізовану інформацію, та на основі яких відбувається налаштування пошукових засобів з метою тонкого підстроювання під освітні інформаційні потреби користувача.
Таким чином, завдяки реалізації повнофункціональної системи, яку розроблено в процесі роботи над проектом, та структурно-алгоритмічної організації програмних засобів надається можливість отримання, структурування, аналізу та обробки даних і надання кінцевому користувачеві високоефективних семантико-орієнтованих пошукових механізмів
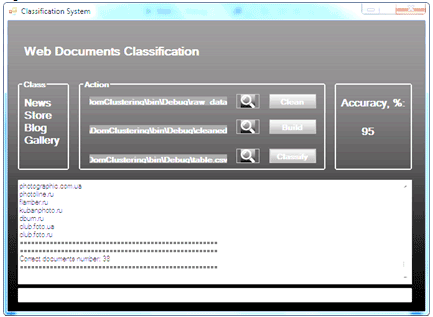
| Долучення | Розмір |
|---|---|
| 390.1 КБ |